首篇文章當然就是先來介紹主角 Observability 可觀測性,Observability 的概念最早由匈牙利裔電機工程師 Rudolf Emil Kálmán 於 1960 年代開始大力推廣,透過系統的輸出來評估系統內部的狀態。經過時間的流轉,原本是應用於機械的概念也開始應用於計算機科學上;到了現代 Observability 也開始應用於軟體領域。就像 DevOps 與 Agile 一樣,對於軟體中的 Observability 如何定義,大家都有很多不同的想法。在 CNCF 的 Glossary Project 以及 Observability Whitepaper 中都有定義 Observability,不過我比較偏愛的是兩年前 Glossary Project 中的 V1 Ready 版本,該版本定義如下:
Observability is a characteristic of an application that refers to how well a system's state or status can be understood from its external outputs. Computer systems are measured by observing CPU time, memory, disk space, latency, errors, etc. The more observable a system is, the easier it is to understand how it’s doing by looking at it.
透過 ChatGPT 翻譯成中文的意思為:
可觀測性是指一個應用程序的特性,指的是從其外部輸出來理解系統狀態或狀態的程度。計算機系統通過觀察 CPU 時間、記憶體、磁碟空間、延遲、錯誤等來衡量。系統的可觀測性越高,通過觀察它來理解它的運行情況就越容易。
當理解系統的狀況時,無論是優化或是排解問題,都會相對輕鬆很多;這也是可觀測性可帶來的效益。

只要你懂系統,系統就會幫助你
那該如何評估或是加強可觀測性呢?在介紹 Observability 時,我通常都會把它概括成一句話:
透過各種資訊,清楚了解系統狀態。
這邊有兩個關鍵字,第一個是「資訊」,第二個是「清楚」。可以針對這兩個關鍵字提問:
第一個問題指向的是資訊不足。若想補強,可以參考 CNCF 在 Observability Whitepaper 中提到的各種 Observability Signal,以補足更多資訊。例如大家耳熟能詳的 Metrics、Logs、Traces。
第二個問題指向的是 Data Silo,即資訊各自為政,無法有效被統合與利用。但資訊格式各異,要如何建立關聯?一樣在 Observability Whitepaper 中的 Correlating Observability Signals 也有舉例。其中一種最直觀是使用時間作為關聯,因為它們終究是呈現某個時間點系統的狀態,觀測相同時間區段的不同資訊,就可以將它們建立連結產成綜效。如何建立關聯只是一種概念,要如何實踐與解決 Data Silo 則是需要依靠工具達成。例如,Grafana 能同時瀏覽同一個時間段內的 Metrics 與 Logs,排查問題時能夠更快理解發生錯誤時系統的狀態,或是系統狀態異常時所紀錄的 Log。其他更多關聯的方式與應用,將會在接下來的工具介紹章節中分享。
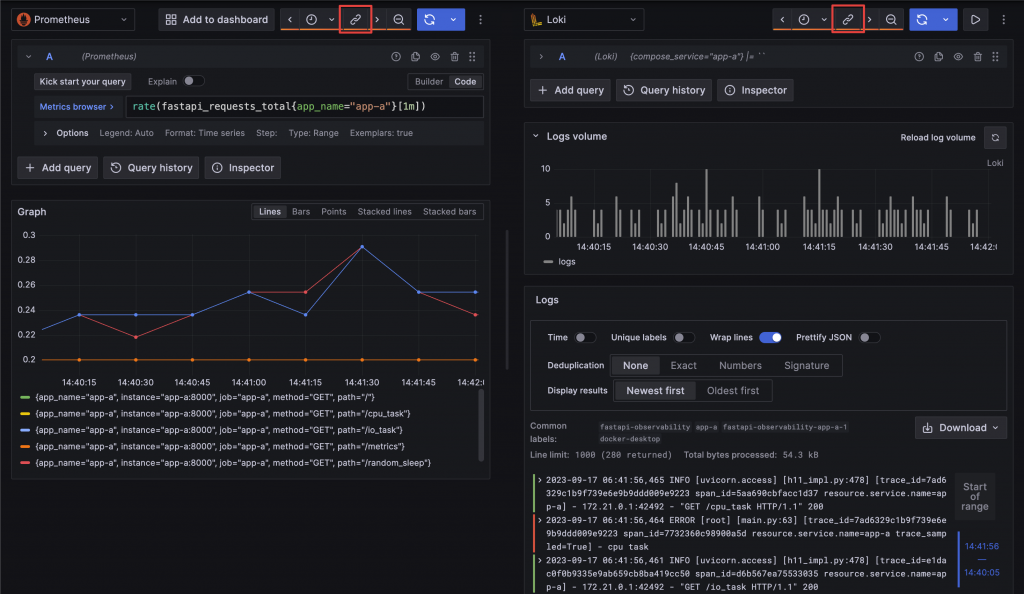
在 Grafana 透過 Sync 功能同步 Metrics 與 Logs 的查詢時間區間
如前所述,要強化系統的 Observability,重點在於收集和利用足夠的 Observability Signals。那麼,這些訊號具體包括哪些內容呢?
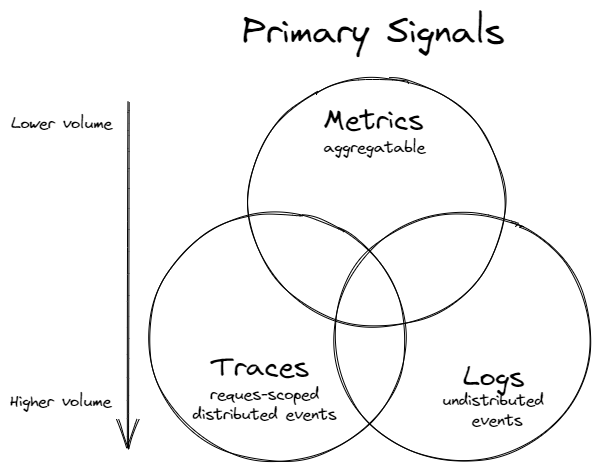
大家最熟悉也最常看到的應該就是三本柱(Three Pillars), Metrics、Logs、Traces。最早公開提出這類概念的可能是 Twitter 在 2016 發表的 Observability at Twitter: technical overview, part I,裡面提到了 Twitter Observability Engineering Team 的四個核心理念(four pillars):
再後來逐漸被大家縮略為常見的 Three Observability Pillars:
不過隨著 Observability 領域的發展,許多人對於 ”Three Observability Pillars” 這個詞開始有一些不同的意見,主要是這樣的定義暗示了缺一不可,否則支撐著的 Observability 屋頂就會倒塌。但實際上,每一種 Signals 都可以獨立提供有價值的可觀測性資訊。因此,在 Observability Whitepaper 中,這些與 Observability 相關的資訊被稱為 Observability Signals,而 Metrics、Logs、Traces 則尊稱為 Primary Signals,同時也列出了其他的 Signals,例如:Profiles、Dumps。
在實際維運和問題排查中,這些 Observability Signals 如何發揮作用呢?我們可以把 Signals 分為兩組:
透過這些 Observability Signals,我們可以從靠通靈 Debug 的通靈王,進化成靠各種跡象、線索拼湊出完整案發現場的福爾摩斯。
在了解了 Observability Signals 之後,接下來我們將探討如何處理和應用這些資訊。整個過程可以分為四個主要階段:
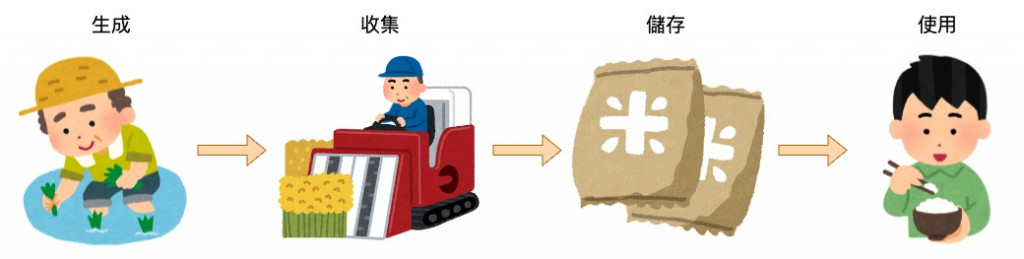
後續的章節會按照這四個階段來介紹相關的工具,並標明他們屬於哪些階段。了解這些工具的階段性特點有助於理解它們如何分工協作,也便於我們在新工具出現時判斷它想解決的痛點是哪部分,以及採用時該如何調整資料流的架構。
在正式開始進入工具介紹前,先理解一些常見的資料收集 Pattern 與名詞對於後續的學習也非常有幫助。
以下是資訊傳遞時常見的模式:
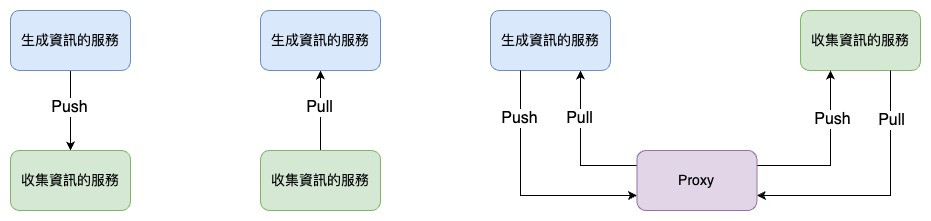
以下是各種工具的元件常用的名字:
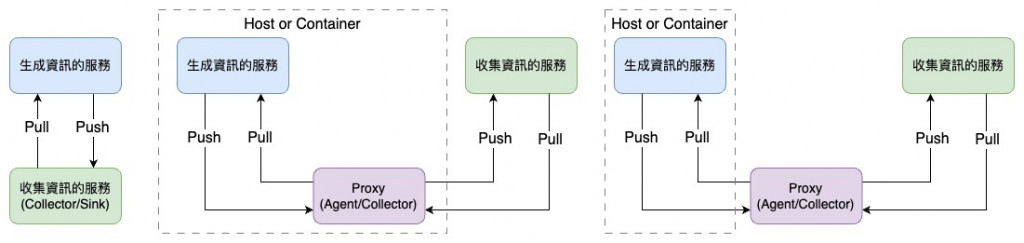
本篇介紹了 Observability 的基礎概念,以及 Observability Signals 的用途和處理流程。下一篇是本系列要介紹的第一個工具,將從已經成為 Observability 標配的視覺化工具 Grafana 開始。
很期待大大今年的分享 還有DevOps Days的分享
小弟剛好是這場的共筆志工
居然是雷N大大!DevOpsDays簡報努力優化中XD
哇 雷N哥